
Machine Learning Methods
Machine LearningSupervised learning is the machine learning task of inferring a function from labeled training data.[1] The training data consist of a set of training examples. In supervised learning, each example is a pair consisting of an input object (typically a vector) and a desired output value (also called the supervisory signal). A supervised learning algorithm analyzes the training data and produces an inferred function, which can be used for mapping new examples. An optimal scenario will allow for the algorithm to correctly determine the class labels for unseen instances. This requires the learning algorithm to generalize from the training data to unseen situations in a “reasonable” way
Unsupervised machine learning is the machine learning task of inferring a function to describe hidden structure from “unlabeled” data (a classification or categorization is not included in the observations). Since the examples given to the learner are unlabeled, there is no evaluation of the accuracy of the structure that is output by the relevant algorithm—which is one way of distinguishing unsupervised learning from supervised learning and reinforcement learning.
Reinforcement learning (RL) is an area of machine learning inspired by behaviourist psychology, concerned with how software agents ought to take actions in an environment so as to maximize some notion of cumulative reward. The problem, due to its generality, is studied in many other disciplines, such as game theory, control theory, operations research, information theory, simulation-based optimization, multi-agent systems, swarm intelligence, statistics and genetic algorithms. In the operations research and control literature, the field where reinforcement learning methods are studied is called approximate dynamic programming.
Techniques
5 supervised learning techniques- Linear Regression, Logistic Regression, CART (Classification and Regression Trees), Gaussian Naïve Bayes, KNN (K-Nearest Neighbors).
3 unsupervised learning techniques- Apriori, K-means, PCA.
2 ensembling techniques- Bagging with Random Forests, Boosting with XGBoost.
Process overview
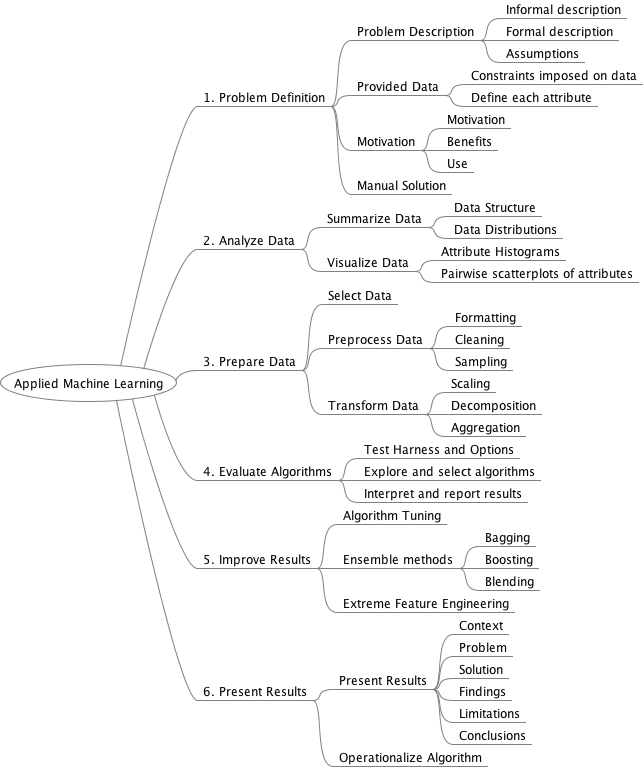
Image credit: https://machinelearningmastery.com/4-steps-to-get-started-in-machine-learning/
Basic steps
- Load dataset
CSV file# Load dataset url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data" names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class'] dataset = pandas.read_csv(url, names=names)Mysql
import MySQLdb mysql_cn= MySQLdb.connect(host='myhost', port=3306,user='myusername', passwd='mypassword', db='information_schema') df_mysql = pd.read_sql('select * from VIEWS;', con=mysql_cn) print 'loaded dataframe from MySQL. records:', len(df_mysql) mysql_cn.close()Oracle
import pandas as pd import cx_Oracle ora_conn = cx_Oracle.connect('your_connection_string') df_ora = pd.read_sql('select * from user_objects', con=ora_conn) print 'loaded dataframe from Oracle. # Records: ', len(df_ora) ora_conn.close()Hive
import pyhs2 with pyhs2.connect(host, port=20000,authMechanism="PLAIN",user,password, database) as conn: with conn.cursor() as cur: #Show databases print cur.getDatabases() #Execute query cur.execute(query) res = cur.getSchema() description = list(col['columnName'] for col in res) ## for getting the column names of the table headers = [x.split(".")[1] for x in description] # for splitting the list if the column name contains a period df= pd.DataFrame(cur.fetchall(), columns = headers) df.head(n = 20) - Summarize the Dataset
- Dimensions of Dataset
# shape print(dataset.shape) - Peek at the data itself
# head print(dataset.head(20)) - Statistical summary of all attributes
# descriptions print(dataset.describe())Example output
sepal-length sepal-width petal-length petal-width count 150.000000 150.000000 150.000000 150.000000 mean 5.843333 3.054000 3.758667 1.198667 std 0.828066 0.433594 1.764420 0.763161 min 4.300000 2.000000 1.000000 0.100000 25% 5.100000 2.800000 1.600000 0.300000 50% 5.800000 3.000000 4.350000 1.300000 75% 6.400000 3.300000 5.100000 1.800000 max 7.900000 4.400000 6.900000 2.500000 - Class Distribution - Breakdown of the data by the class variable
# class distribution print(dataset.groupby('class').size())
- Dimensions of Dataset
- Data visualization
- Univariate Plots - individual variable
# box and whisker plots dataset.plot(kind='box', subplots=True, layout=(2,2), sharex=False, sharey=False) plt.show()# histograms dataset.hist() plt.show() - Multivariate plots - intersections between variables)
# scatter plot matrix scatter_matrix(dataset) plt.show()
- Univariate Plots - individual variable
- Evaluate Some Algorithms
Example:- Separate out a validation dataset.
We will split the loaded dataset into two, 80% of which we will use to train our models and 20% that we will hold back as a validation dataset.# Split-out validation dataset array = dataset.values X = array[:,0:4] Y = array[:,4] validation_size = 0.20 seed = 7 X_train, X_validation, Y_train, Y_validation = model_selection.train_test_split(X, Y, test_size=validation_size, random_state=seed) - Set-up the test harness to use 10-fold cross validation.
- Build 5 different models to predict species from flower measurements
- Select the best model.
- Separate out a validation dataset.
- Make predictions on validation dataset
Reference:
https://en.wikipedia.org/wiki/Supervised_learning
https://en.wikipedia.org/wiki/Unsupervised_learning
https://en.wikipedia.org/wiki/Reinforcement_learning
https://www.kdnuggets.com/2017/10/top-10-machine-learning-algorithms-beginners.html
https://www.kdnuggets.com/2016/08/10-algorithms-machine-learning-engineers.html
https://machinelearningmastery.com/machine-learning-in-python-step-by-step/
Machine Learning (Python) class