
Hive vs Pig
Hive Pig Bigdata Machine Learning Hadoop| Pig | Hive |
|---|---|
| Procedural Data Flow Language | Declarative SQLish Language |
| For Programming | For creating reports |
| Mainly used by Researchers and Programmers | Mainly used by Data Analysts |
| Operates on the client side of a cluster. | Operates on the server side of a cluster. |
| Does not have a dedicated metadata database. | Makes use of exact variation of dedicated SQL DDL language by defining tables beforehand. |
| Pig is SQL like but varies to a great extent. | Directly leverages SQL and is easy to learn for database experts. |
| Pig supports Avro file format. | Hive does not support it. |

| Characteristic | Pig | Hive |
|---|---|---|
| Language Name | Pig Latin | HiveQL |
| Type of Language | Dataflow | Declarative (SQL Dialect) |
| Developed By | Yahoo | |
| Data Structures | Supported | Nested and Complex |
| Relational Complete | YES | YES |
| Schema Optional | YES | NO |
| Turing Complete | YES,when you extend it with Java User Defined Functions. | YES, when you extend it with Java User Defined Functions. |
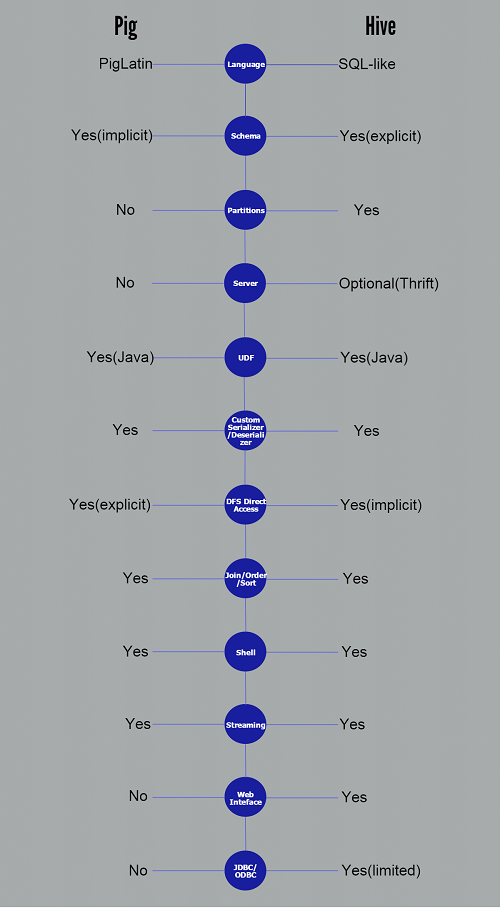
Depending on your purpose and type of data you can either choose to use Hive Hadoop component or Pig Hadoop Component based on the below differences :
1) Hive Hadoop Component is used mainly by data analysts whereas Pig Hadoop Component is generally used by Researchers and Programmers.
2) Hive Hadoop Component is used for completely structured Data whereas Pig Hadoop Component is used for semi structured data.
3) Hive Hadoop Component has a declarative SQLish language (HiveQL) whereas Pig Hadoop Component has a procedural data flow language (Pig Latin)
4) Hive Hadoop Component is mainly used for creating reports whereas Pig Hadoop Component is mainly used for programming.
5) Hive Hadoop Component operates on the server side of any cluster whereas Pig Hadoop Component operates on the client side of any cluster.
6) Hive Hadoop Component is helpful for ETL whereas Pig Hadoop is a great ETL tool for big data because of its powerful transformation and processing capabilities.
7) Hive can start an optional thrift based server that can send queries from any nook and corner directly to the Hive server which will execute them whereas this feature is not available with Pig.
8) Hive directly leverages SQL expertise and thus can be learnt easily whereas Pig is also SQL-like but varies to a great extent and thus it will take some time efforts to master Pig.
9) Hive makes use of exact variation of the SQL DLL language by defining the tables beforehand and storing the schema details in any local database whereas in case of Pig there is no dedicated metadata database and the schemas or data types will be defined in the script itself.
10) The Hive Hadoop component has a provision for partitions so that you can process the subset of data by date or in an alphabetical order whereas Pig Hadoop component does not have any notion for partitions though might be one can achieve this through filters.
11) Pig supports Avro whereas Hive does not.
12) Pig can be installed easily over Hive as it is completely based on shell interaction
13) Pig Hadoop Component renders users with sample data for each scenario and each step through its “Illustrate” function whereas this feature is not incorporated with the Hive Hadoop Component.
14) Hive has smart inbuilt features on accessing raw data but in case of Pig Latin Scripts we are not pretty sure that accessing raw data is as fast as with HiveQL.
15) You can join, order and sort data dynamically in an aggregated manner with Hive and Pig however Pig also provides you an additional COGROUP feature for performing outer joins.
16) Pig and Hive QL are not turing complete unless extended with Java UDF’s.
17) Apache Pig is the most concise and compact language compared to Hive.
18) Hadoop Pig and Hive Hadoop outperform hand-coded Hadoop MapReduce jobs as they are optimised for skewed key distribution.
Pig vs. Hive- Performance Benchmarking
Apache Pig is usually more efficient than Apache Hive as it has many high quality codes. When implementing joins, Hive creates so many objects making the join operation slow. Here are the results of Pig vs. Hive Performance Benchmarking Survey conducted by IBM –
- Apache Pig is 36% faster than Apache Hive for join operations on datasets.
- Apache Pig is 46% faster than Apache Hive for arithmetic operations.
- Apache Pig is 10% faster than Apache Hive for filtering 10% of the data.
- Apache Pig is 18% faster than Apache Hive for filtering 90% of the data.